Sibyl: A Practical Internet Route Oracle
论文Calder, Matt, Yi-Ching Chiu, and Brandon Schlinker. “Sibyl: A Practical Internet Route Oracle.”
网络路由(Internet Route),描述两点之间的路由路径,经常用于解决网络问题或者是用于描述网络。
目前的形式
现在获取网络路由的还是一些老的工具,例如路由跟踪(traceroute)、BGP route collectors以及Looking Glasses等。
有很多公开的测量平台可以使用,它们提供遍布整个世界的vantage points来发起traceroute,
例如RIPE Atlas、PlanetLab、Traceroute servers、DIMES、Dasu。
可以通过这些平台来发起traceroute,但是这样的查询方式存在很多的限制:
- 没有将历史的查询与实时的查询相结合。
- 平台与平台之间是独立的。
- 只能接受一个简单的question:“What is the path from here to there?”
- 因为是公开的平台,它们有资源限制。
这导致目前的路由跟踪所能获得的信息十分有限,通常只能回答一些简单的问题。
Sibyl
论文提出一个网络路由查询系统,Sibyl[‘sɪbɪl]。
Sibyl提供正则表达式形式的查询,查询形式十分丰富,例如“在亚特兰大地区,哪些路由穿过Level3但是又不经过AT&T?”。
为了满足查询,它的后端将从多种vantage points中发起traceroute,也就是使用多个测量平台来加快收敛。
问题:测量平台存在资源限制。由于一些查询需要发起很多的traceroute,它们都可能可以满足查询,
但是由于资源限制,不可能做到。
为了解决这个问题,需要下面三个步骤:
- 根据查询的结构缩小需要发出的
traceroute,使得问题专注到一小部分traceroute。(正则表达式的结构) - 结合历史数据来预测哪些未发出的
traceroute更可能匹配到查询。(iPlane、RuleFit) - 根据预测来最优化测量的资源分配。(贪心算法)
Sibyl 结构

- UI界面。
- 一批Query。
- 预测与Query相匹配的路径。
- 最优化资源的利用。
- 结合多个平台执行测量。
- 测量结果与Query比较,返回满足的测量结果。
- 查看当前Model的数据是不是过时,如果过时,就用本次的测量结果去更新它。
Query与正则表达
Query的两种类型,一种是查询一条路径,例如查询从特定的源到目的的路径;
另一种是查询一个路径的集合,例如查询经过某个特定AS link的所有路径,为了知道哪些源目对使用了这条路径。
它们均使用正则表达式来表达,下面是文中给出的一些例子:
Reverse traceroute:查询从r到s的路径:
Detecting prefix hijacks with iSpy:查询所有能够到达p的AS:
其中的$\wedge$表示反方向也需要查询。
预测部分
首先使用iPlane来预测一条未经测量的路径是否有可能匹配查询。
然后RuleFit来对预测出来的路径分配置信度。
iPlane
iPlane使用路径拼接的方法去预测一条没有测量过的路径。
例如预测从s到d的路径,iPlane将从s出发到某个目的的路径, 与从某个源出发目的为d的两条路径进行拼接,这两条路径需要存在相交的点。
原始的iPlane存在的问题:
- 对一个点对s到d之间会选出一条最好的预测路径,但这条路径可能是错的。
- 对于预测出的路径没有置信度,这不利于测量资源的分配。
解决思路:
- 考虑s到d之间所有预测出的路径。
- 给予这些路径赋予置信度。
RuleFit
RuleFit是一种监督学习的方法,这里使用它来给拼接的路径分配权重。
训练大概流程:先取出路径的很多属性,使用RuleFit可以计算出各个属性的重要程度(内部使用decision trees或者lasso constraints),
The score for a spliced path is the sum of rule values for rules that match the spliced path’s features
if the spliced path’s AS-path length is among the shortest, then increase the confidence (score) that it is very similar to > the actual path
使用拼接路径的一些属性,RuleFit可以给出与真实路径之间相似程度分数。
最优化资源的利用

直接使用贪心的方法去近似的解决这个问题,每次选择使得期望utility最大的traceroute。
结合多个平台
结合到多个平台可以提高系统的覆盖范围,每个平台都提供了很多vantage points,它们之间存在不重合的部分,
将它们结合到一起可以得到Path diversity的提升。


论文附录例子
假如有三条已存在的traceroute:

为了简单这里IP的前八位就代表它是哪个AS。
查询问题,进过AS2和AS9的所有路径:
首先将问题转化为FSA(论文没有找到FSA的具体说明):
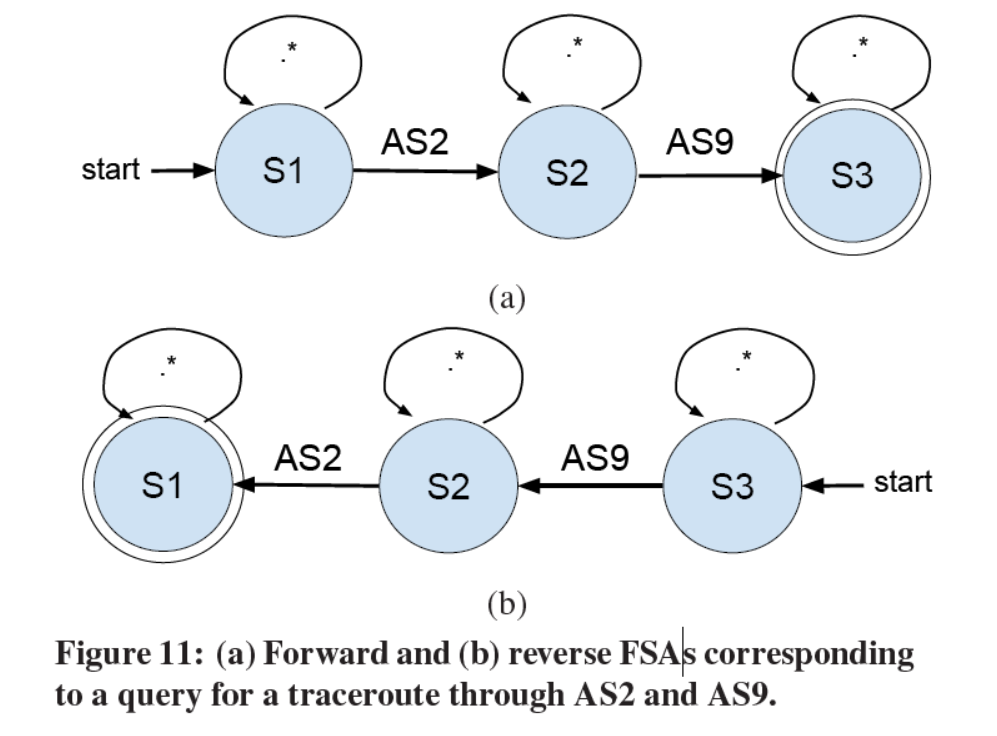
然后建立起前向和后向的两张表:

对左边的前向表进行一下解释(右表同理):
- 表的第一行$S_1 \xrightarrow[]{.*} S_1$,表示路径的起点,所以这里所有的AS都可以作为起点。
- 表的第二行$S_1 \xrightarrow[]{AS2} S_2$,表示从起点开始,经过AS2,所以只有第一行中的
Trace 1的AS2满足。 - 表的第三行$S_2 \xrightarrow[]{.*} S_2$,表示S2可以向后扩展(也就是上一行中的AS2),这里就可以扩展到
3,4,5。 - 第四行向后没有满足的路径。
将前向后向路径拼接到一起,这里就可以从S2的位置拼接,前向路径1->2->3,后向路径13->9->3,
于是就得到路径1->2->3->9->13。
Likelihood estimation:
假如拼接得到以下的路径:

对于1.0.0.1到13.0.0.1拼接得到两条路径,其中路径A满足查询,路径B不满足,进行归一化0.41 = 0.7x0.7/(0.7 + 0.5),
0.29 = 0.7x0.5/(0.7 + 0.5),由于路径B不满足查询,所以最后1.0.0.1到13.0.0.1的likelihood为0.41。
对于15.0.0.1到16.0.0.1拼接得到两条路径,其中路径C、D都满足查询,进行归一化0.3 = 0.6x0.6/(0.6 + 0.6),
0.3 = 0.6x0.6/(0.6 + 0.6),所以最后15.0.0.1到16.0.0.1的likelihood为0.3 + 0.3 = 0.6。
所以这里路径15.0.0.1到16.0.0.1满足查询的概率大于路径1.0.0.1到13.0.0.1。